Accès instantané à des millions de traductions de grande qualité
Plus besoin créer de façon laborieuse une base de données ne contenant que des phrases complètes hors contexte associées à leurs traductions préalables. L’approche se fondant sur les corpus permet plutôt d’indexer très rapidement un vaste recueil de documents de référence (textes de départ et d’arrivée), grâce à des techniques avancées de recherche. Une telle approche utilise également des algorithmes évolués, aux fins d’alignement des textes de départ avec leurs textes d’arrivée correspondants. Ainsi, un corpus contenant plusieurs millions de mots peut être créé en l’espace de moins d’une heure. Une base de données de MT de taille équivalente exigerait des années de travail!
Au lieu de créer un seul corpus volumineux, MultiTrans vous permet de créer, en quelques minutes seulement, plusieurs corpus cibles, et ce, en important tout texte pertinent, peu importe la langue. En plus d’utiliser vos propres projets de traduction, vous pouvez également exploiter avantageusement tout autre contenu accessible librement, y compris des contenus disponibles sur le Web. Par exemple, dans le cas d’un projet de traduction portant sur les soins de santé, vous pouvez importer en un clin d’œil une vaste quantité de textes trilingues (anglais, français et espagnol) pertinents, à partir du site Web de l’Organisation mondiale de la santé, et les rendre immédiatement accessibles dans le cadre de vos activités de traduction.
La création rapide de vastes corpus de référence et leur consultation facile vous donnent ainsi accès à d’imposants recueils de textes monolingues ou multilingues et à des travaux exemplaires en matière de rédaction, d’usage terminologique et de traductions.
Alignement à la volée : aucun investissement initial
L’alignement des textes de départ et d’arrivée n’est pas toujours parfait, et ce, même si le système utilise les algorithmes d’alignement les plus avancés qui soient. Des désalignements surviennent fréquemment, par exemple lorsqu’une phrase dans le texte de départ a été traduite en plusieurs phrases dans le texte d’arrivée. Puisque de tels désalignements résultent habituellement en un simple décalage d’une ou deux phrases, vous pouvez alors déceler le problème en un coup d’œil dans les zones de la fenêtre de travail. Il vous suffit de corriger la situation à la volée, à l’aide de quelques clics; le corpus se trouve ainsi continuellement revu et amélioré. Contrairement aux bases de données de mémoire de traduction, l’alignement parfait du corpus n’est pas une nécessité, ce qui élimine le long processus de vérification préalable des textes avant d’utiliser la base de données à des fins pratiques.
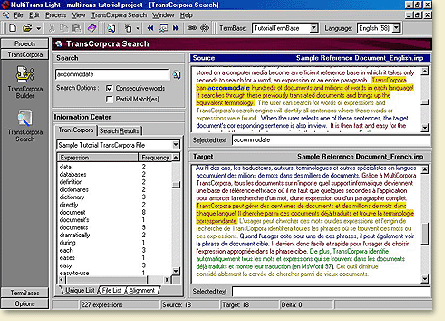
Consultez des expressions dans leur contexte et de toutes longueurs
Vous pouvez facilement effectuer une recherche dans tout le corpus, peu importe la longueur de l’expression recherchée, et dans toutes les langues du corpus.